Furiganalyse
Annotate Japanese ebooks with readings
Stack: Python, FastAPI
Try it here
Code on GitHub
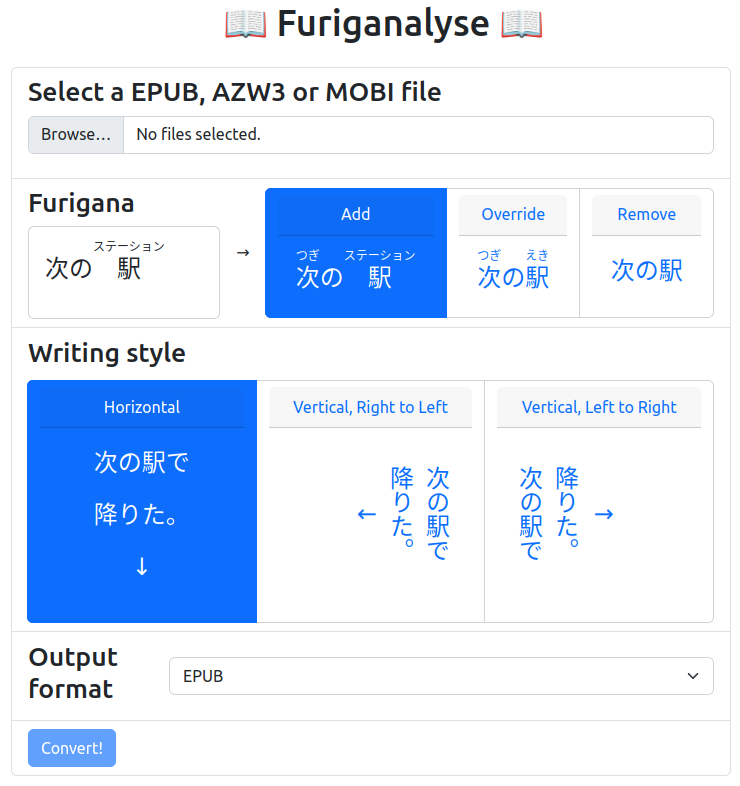
Problem
I love reading Japanese ebooks, but I struggled with the lack of furigana (the readings of kanji characters). What difference does it make? Here is an example:
- Without readings
そのため、台湾の人々は「なぜ新型コロナウイルスの対策を厳重にしなければならないか」という理由をよく理解しています。
- With all readings:
そのため、台湾の人々は「なぜ新型コロナウイルスの対策を厳重にしなければならないか」という理由をよく理解しています。
Books intended for adult natives have no readings because they know how to read the characters (duh!), except for rare words/kanjis.
As a Japanese learner without a lot of reading experience, this means that I would have to look up a lot of words just to check their reading, which takes a few seconds each time on a Kindle and gets in the way of the reading experience.
Solution
I created a Python library and web app that allows you to upload an ebook, and it will return a copy of that ebook with furigana added… all of them!
I further extended it to export to other formats, such as an Anki deck (for flashcards) or an HTML file (for reading in a web browser).

Challenges
Parsing Japanese text is not trivial: even tokenizing characters into words is not straightforward, because there are no spaces between words, and how words are composed of smaller words 1. But finding the correct reading for each word is even harder, as there are many possible readings for a single word, and the correct reading depends on the context! I could leverage an existing library to get started, but I had to improve it a lot and fix many edge cases. Thorough unit testing proved to be very useful. The results are not perfect, but they are good enough for my use case.
While EPUB is a standard format for ebooks, there are subtle variations in the metadata, the HTML tags used or the encoding. I had to test it on ebooks coming from various sources to deal with all these cases. But I learned a lot about ebook formats in the process!
Finally, a framework like FastAPI is designed for static websites, not for dynamic usages like handling the conversion tasks running in the background (it can take a while for big books!). I made it work with a simple hack: using an AJAX request to poll the status of the task, and redirecting the user to the download page when it is done. I made a minimal example of this here.
-
Check out this great article for more details ↩